Welcome to Flambé¶
Welcome to Flambé, a PyTorch-based library that allows users to:
- Run complex experiments with multiple training and processing stages.
- Search over an arbitrary number of parameters and reduce to the best trials.
- Run experiments remotely over many workers, including full AWS integration.
- Easily share experiment configurations, results and model weights with others.
Visit the github repo: https://github.com/asappresearch/flambe
A simple Text Classification experiment
!Experiment
name: sst-text-classification
pipeline:
# stage 0 - Load the Stanford Sentiment Treebank dataset and run preprocessing
dataset: !SSTDataset
transform:
text: !TextField
label: !LabelField
# Stage 1 - Define a model
model: !TextClassifier
embedder: !Embedder
embedding: !torch.Embedding # automatically use pytorch classes
num_embeddings: !@ dataset.text.vocab_size
embedding_dim: 300
embedding_dropout: 0.3
encoder: !PooledRNNEncoder
input_size: 300
n_layers: !g [2, 3, 4]
hidden_size: 128
rnn_type: sru
dropout: 0.3
output_layer: !SoftmaxLayer
input_size: !@ model[embedder][encoder].rnn.hidden_size
output_size: !@ dataset.label.vocab_size
# Stage 2 - Train the model on the dataset
train: !Trainer
dataset: !@ dataset
model: !@ model
train_sampler: !BaseSampler
val_sampler: !BaseSampler
loss_fn: !torch.NLLLoss
metric_fn: !Accuracy
optimizer: !torch.Adam
params: !@ train[model].trainable_params
max_steps: 10
iter_per_step: 100
# Stage 3 - Eval on the test set
eval: !Evaluator
dataset: !@ dataset
model: !@ train.model
metric_fn: !Accuracy
eval_sampler: !BaseSampler
# Define how to schedule variants
schedulers:
train: !ray.HyperBandScheduler
The experiment can be executed by running:
flambe experiment.yaml
Tip
All objects in the pipeline are subclasses of Component, which
are automatically registered to be used with YAML. Custom Component
implementations must implement run() to add custom
behavior when being executed.
By defining a cluster:
!AWSCluster
name: my-cluster # Make sure to name your cluster
factories_num: 2 # Number of factories to spin up, there is always just 1 orchestrator
factories_type: g3.4xlarge
orchestrator_type: t3.large
key: '/path/to/ssh/key'
...
Then the same experiment can be run remotely:
flambe experiment.yaml --cluster cluster.yaml
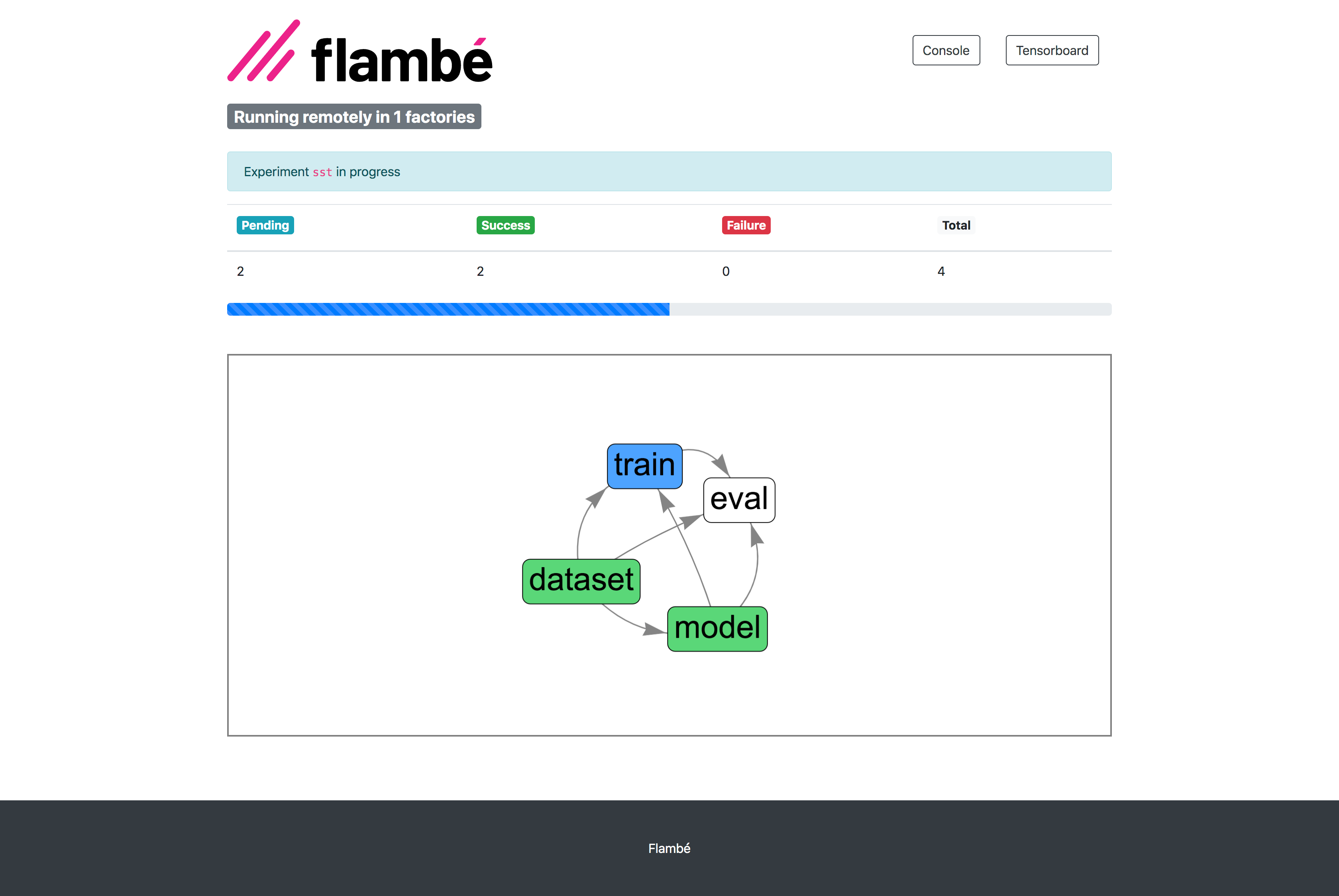
Progress can be monitored via the Report Site (with full integration with Tensorboard):
Getting Started
Check out our Installation Guide and Quickstart sections to get up and running with Flambé in just a few minutes!